
Adam Wathan expuso una charla increíble sobre TDD y la diferencia entre escribir pruebas unitarias VS escribir pruebas funcionales. En este artículo podrás leer una suerte de resumen / interpretación personal de los conceptos expuestos por Adam y obtendrás recursos para comenzar a escribir o mejorar tus pruebas automatizadas.
Si ya has aprendido TDD o estás comenzando a leer sobre pruebas automatizadas, es posible que hayas leído algunas mentiras como por ejemplo:
- Todas tus pruebas deberían ser unitarias
- Tus pruebas no deberían interactuar con la base de datos
- Si no puedes probar tu código de forma aislada, está pobremente diseñado
Esta filosofía lleva a la sobre-ingeniería de código, es decir sobre complicar nuestro código muchas veces de forma innecesaria.
Por ejemplo cuando intentamos separar o desacoplar la lógica de nuestra aplicación del framework o de la base de datos podemos terminar escribiendo:
- Commandos (Command Bus)
- Transportes
- Handlers
- Repositorios
- Interfaces
Lo cual nos lleva a crear demasiadas clases y capas de abstracción para crear un simple CRUD.
Además este tipo de diseño irónicamente puede hacer que tus pruebas no solamente sean más difíciles de escribir, sino que pierdas una de las habilidades y propósitos principales de escribir pruebas automatizadas:
Las pruebas deberían permitirte refactorizar tu código sin tener que reescribir la prueba.
De hecho el flujo de TDD (test driven development) es (aproximadamente):
- Escribir una prueba
- Ejecutar la prueba (esperar que falle)
- Escribir código
- Volver a ejecutar la prueba hasta que pase (si falla regresar al punto 3)
- Refactorizar el código
Si escribir pruebas completamente independientes o aisladas del framework o de la base de datos no nos permite refactorizar nuestro código sin romper las pruebas, podemos concluir que escribir pruebas de esa manera puede ser incompatible con TDD.
Feature tests
Por otro lado las pruebas funcionales (también conocidas como pruebas de aplicación o integración) que prueban interactuando con HTTP, base de datos, framework, etc. son más flexibles en el sentido que nos permiten refactorizar la implementación de nuestro código sin requerir cambios o refactorización en la prueba.
¿Qué hay de servicios externos?
Aunque interactuar con la base de datos en una prueba puede resultar no ser un problema en lo absoluto (no es tan lento ni tan difícil como puedas creer inicialmente), interactuar como APIs (por ejemplo Stripe) puede hacer que nuestra prueba se vuelva bastante lenta o que no nos permita probar sin conexión a Internet, etc. Es allí donde debemos utilizar alternativas como mocks o fakes para reemplazar la implementación de dichos servicios.
Diferencia entre mock y fakes
En vez de crear mocks utilizando libraries como Mockery, etc. otra forma que podemos escribir nuestras pruebas es usando fakes
En este caso podemos definir una interfaz con los métodos que necesitamos, y crear 2 clases:
- Una implementación real
- Una implementación “de mentira”
Un ejemplo de esta práctica son los drivers de “array” que incluye Laravel para caché o sesión, que en vez de crear variables de sesión simplemente almacenan todo en un array.
Separando las fronteras de nuestra aplicación
En vez de intentar separar nuestra aplicación en pequeñas capas como «base de datos», «validación», «controladores» podemos decir que nuestra aplicación que se conecta a través del protocolo HTTP tiene 3 partes principales:
- Petición (request)
- Proceso
- Respuesta (response)
Como podemos ver en el gráfico que compartió Adam durante la conferencia:
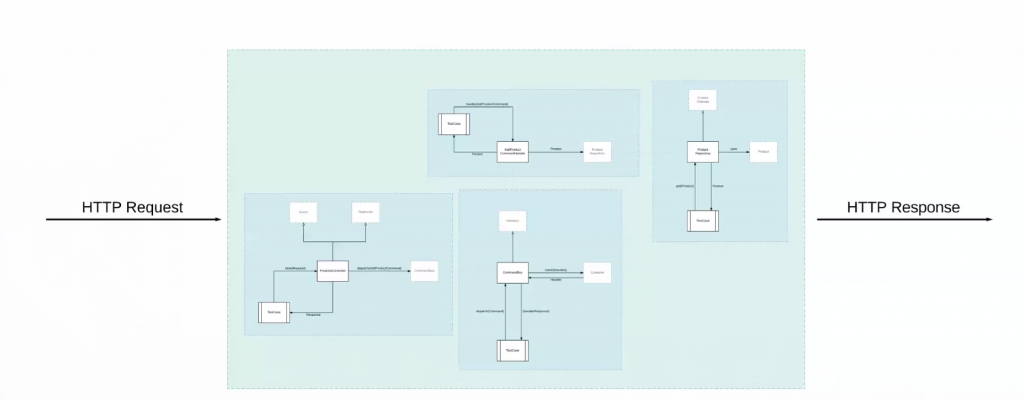
Nos permite simplificar mucho nuestra mentalidad a la hora de escribir pruebas, porque sólo nos concentraremos en preparar y simular el envío de la petición al framework (por ejemplo $this->post('products', ['product_data']) y luego verificar que obtenemos la respuesta correcta (por ejemplo JSON o HTML) o que nuestra aplicación registró ciertos datos en la base de datos o que nuestros objetos «Fake» contengan ciertos datos.
De esta manera siempre que la petición sea la misma y la respuesta esperada sea la misma, deberíamos ser capaces de refactorizar nuestro código sin tener que modificar nuestra prueba, lo cual es parte del propósito de TDD.
¿Quieres aprender más sobre pruebas automatizadas y TDD?
Puedes aprender más sobre TDD con el curso de Adam Wathan «Test Driven Laravel» y también puedes aprender sobre pruebas y TDD aquí en Styde.net:
- Crea una aplicación con Laravel y TDD
- Diferencias entre pruebas unitarias, de integración y aplicación
- Cómo escribir pruebas de aplicación y porqué es importante
Más sobre Laracon Online
Durante el día de hoy te mantendremos al tanto de lo que se esté presentando en las diferentes conferencias:
- Jeffrey Way “Laravel Mix.”
- Evan You “Something Vue.js 2.2+ related”
- Rachel Andrew “CSS Grid and Flexbox.”
- Taylor Otwell “Laravel 5.4 internals walkthrough.”
- Nick Canzoneri “What developers should know about email.”
- Jason McCreary “You don’t know Git.”
- Matt Stauffer “Mastering the Illuminate Container.”
Regístrate hoy en Styde y obtén acceso a todo nuestro contenido.